基于命名实体识别解析动画文件名
起因
起因是因为我在 bangumi 上看到一个帖子,记录了怎么自动化追番的技术分享,我自己通常都是使用 qbittorrent 配合 samba,调用本地播放器打开播放。
流程里面有一个环节就是下载资源之后,会分析视频文件名,获取到资源关联的番剧名称、剧集信息等。我找到了一些相关的库:
anitomy: 使用 C++ 编写
aniparse: anitomy 的 python 重新编写板版本
在 reddit 社区也有一些讨论贴可以参考:
Looking people for Anime Filename Parser project
这些库是都是将文件名转换成 token 流,之后进行固定算法的分析,比较大的压制组和字幕组发布资源的时候,文件名称都有一定的规律,基本能匹配的上。
然后我自己就手痒了,如果只是按照别人的帖子搭建一个同样的系统,我觉得没意思,然后就想着自己也搞一个类似的东西,然后就想到用机器学习训练一个模型能分析文件名,能从文件名里面提取到信息,提取的信息包括下面维度:
- 动画名称
- 制作组
- 集数
- 视频封装格式
- 音频分装格式
- 字幕语言

动手
输入信息是单个资源文件名称,embedding 就比较简单,一个字符一个字符的输入,英文字母数字加上一些符号,做一个偏移即可都不需要搞字典。
- ASCII 可显示字符 (0x20-0x7E)
- 超出 ASCII 范围的,统一成其他字符
因为机器学习什么的我是完全不会,Python 我也不懂,都是边做边学。一开始我想着直接用 CNN 模型,然后全部数据喂进去,统一长度不够的地方使用 padding,想了半天想不出怎么写,然后我就去问 ChatGPT,说遇到类型的情况需要怎么解决,ChatGPT 就唏哩哗啦的输出一大堆东西,大概意思就是这种情况叫做命名实体识别(NER),解决办法有 hmm / crf / lstm-crf 之类的解决方案,知道这个之后,我就去搜索相应的资源,主要是 CRF 是什么东西。
我花了很多时间企图去理解模型背后的那些数学公式,但是那些都是白费力气,直到最后我还是什么都不懂。
后来我偶然看到一篇文章:搭建Pytorch BiLSTM-CRF NER模型踩坑记录
仔细读完之后,给我感觉就是这东西虽然我不是很明白,但是我按照说明书一步步折腾下来,也是能搞出一个差不多的模型。我看到作者贴的代码基本没有修改过,pytorch 官方也有一个 lstm-crf 的例子:
我就对照着这个例子修改,修改的部分是输入还有输出,中间模型的算法不需要去修改。然后修改完之后发现这一部分意外的白痴,模型就像黑盒一样,规定好输入输出,其他的不用管。
接下来就是标记数据,我采用的是 BIO 的方式标记数据,我准备的数据大概有2000条,我花了很多时间在准备这些数据,采用的 json 格式:
{
"title": "[Comicat&KissSub][Karakai Jouzu no Takagi-san S3][08][1080P][GB][MP4].mp4",
"marks": {
"maker": {
"start": 1,
"length": 15
},
"title": {
"start": 18,
"length": 27
},
"season_number": {
"start": 47,
"length": 1
},
"episode_number": {
"start": 50,
"length": 2
},
"resolution": {
"start": 54,
"length": 5
},
"language": {
"start": 61,
"length": 2
}
}
}
然后加载这些数据,输入的数据简单说就是如果是 ascii 可见字符就添加一个偏移值,如果是其他特定的字符就查询 cjk_dict 获取保留字符对应的数值。输出数据根据 BIO 编码,有一个 dict 规定了这些编码。
def code(c: str):
if c in cjk_dict:
return cjk_dict[c]
if ord(c[0]) in range(0x20, 0x7E + 1):
return ord(c[0]) - 0x20
return 95
def tag(marks: dict, idx: int):
for key in marks:
m = marks[key]
if m['start'] <= idx < m['start'] + m['length']:
return tags[key] if m['start'] == idx else tags[key] + 1
return 0
def load(filename: str):
data = []
with open(filename, "r") as f:
arr = json.load(f)
for row in arr:
x = [code(c) for c in row['title']]
y = [tag(row['marks'], i) for i in range(len(x))]
data.append([torch.tensor(x, dtype=torch.long), torch.tensor(y, dtype=torch.long)])
return data
标记和训练的数据有两个来源:
- 直接从种子分享网站上获取
- 从 dht 网络上爬取
从网站上爬取,我爬取了一个网站数千种子然后 IP 被封。然后我又整了一个 dht 爬虫,爬虫使用别人编写好的库,我只需要微调参数即可,期间我还去阅读 dht 协议不过基本也是浪费时间。爬虫倒是勤快,一天爬个 1~2 w 的种子,筛选出视频资源然后用这些视频资源文件名做标记。但是 dht 网络上的视频资源基本都是 18+ 内容,对于正常的电影电视剧资源则较少。
混合了这两部分的内容,之后就是标记,我编写了一个标记面板,采用的是 Vue3 框架。刚刚开始的时候,采用关键字匹配加上手动标记的模式,标记了七八百的数据,然后丢给模型训练出第一版的模型。然后用这个模型作为基础搭建了一个 api,然后调用这个 api 查询,查询完之后再手动修改部分记录的方式,快速标记后续的数据。
期间还重写了标记面板,标记面板第一版的数据直接保存在内存里面,网页刷新一下就没有了,第二版的标记面板改用 indexedDB,能够保存标记进度,又恶补了 indexedDB 相关接口文档。
这时候训练出来的模型已经能正常识别出文件名包含的主要信息,主要信息包括标题剧集号码视频编码音频编码分辨率。如果是动画文件名准确率非常高,对于非动画的视频资源错误就比较明显。感觉主要原因是训练样本的问题,从某资源分享网站下载下来的 bt 种子里面的命名模式非常固定,而且也比较规范,这一部分占训练样本的大多数。另外一部分是 dht 网络上爬取的视频资源,命名模式千奇百怪,对于比较奇葩的记录,我是直接过滤掉,标记的部分也比较随意,有时候我都不知道标记是否正确。因为没有支持 ascii 外的字符,所以如果文件名里面包含了 cjk 字符,效果也比较差,但如果是 cjk 的标题,其实也是能识别出来。
通过微调模型参数还有增加训练数据,到了这里基本已经可用,但是有一个问题,就是模型保存格式是 pytorch 自有的格式,Python 调用没有什么问题,如果供其他语言调用则很麻烦。解决这个问题有两个方向:
- 使用 Python 编写一个 API 接口,其他编程语言直接请求这个接口。
- 转换成 onnx 开放格式,使用 onnx-runtime 调用。
第一种方案实现起来没有什么难度,一下子就搞定了,但是得保留一个后台服务非常的不优雅。测试命令:
curl "http://localhost:5000/?q=%5BSuzumiya_Haruhi_chan_no_Yuuutsu%5D%5BGB_BIG5%5D%5B20%5D%5BDVDRIP%5D%5Bx264_AAC%5D.mkv"
返回内容:
[
{
"length": 31,
"start": 1,
"tag": "title",
"text": "Suzumiya_Haruhi_chan_no_Yuuutsu"
},
{
"length": 7,
"start": 34,
"tag": "language",
"text": "GB_BIG5"
},
{
"length": 2,
"start": 43,
"tag": "episode_number",
"text": "20"
},
{
"length": 6,
"start": 47,
"tag": "source",
"text": "DVDRIP"
},
{
"length": 4,
"start": 55,
"tag": "video",
"text": "x264"
},
{
"length": 3,
"start": 60,
"tag": "audio",
"text": "AAC"
}
]
第二个转换成开放的格式,我各种查询资料,然后各种踩坑,发现 Go 语言竟然没有一个完整 onnx-runtime,总之结论就是我导出来的模型,无法通过 Go 直接调用运行。倒是 js 语言有官方支持,能调用模型,包括网页端。不过还是遇到一个问题,就是预测出来的结果还需要进行维特比解码,然后模型带出来的数据没有包括维特比解码需要的参数,我得自己手动生成一个 json 附带文件,然后编写一段维特比解码的算法,那个对我来说非常的难,但实际写出来的代码就几十行吧。
生活中就是各种坑,对于自己的知识范围之外的东西,要弄明白需要花费非常多的时间还有精力,而且之后还不一定能再次用上。
其他
2022-12-18 开始出现想法,到 2022-12-26 全部编写完成,大概花了一周多时间,踩了坑,然后完成差不多了,又觉得很没意思就把代码全部扔到仓库了。
标记面板
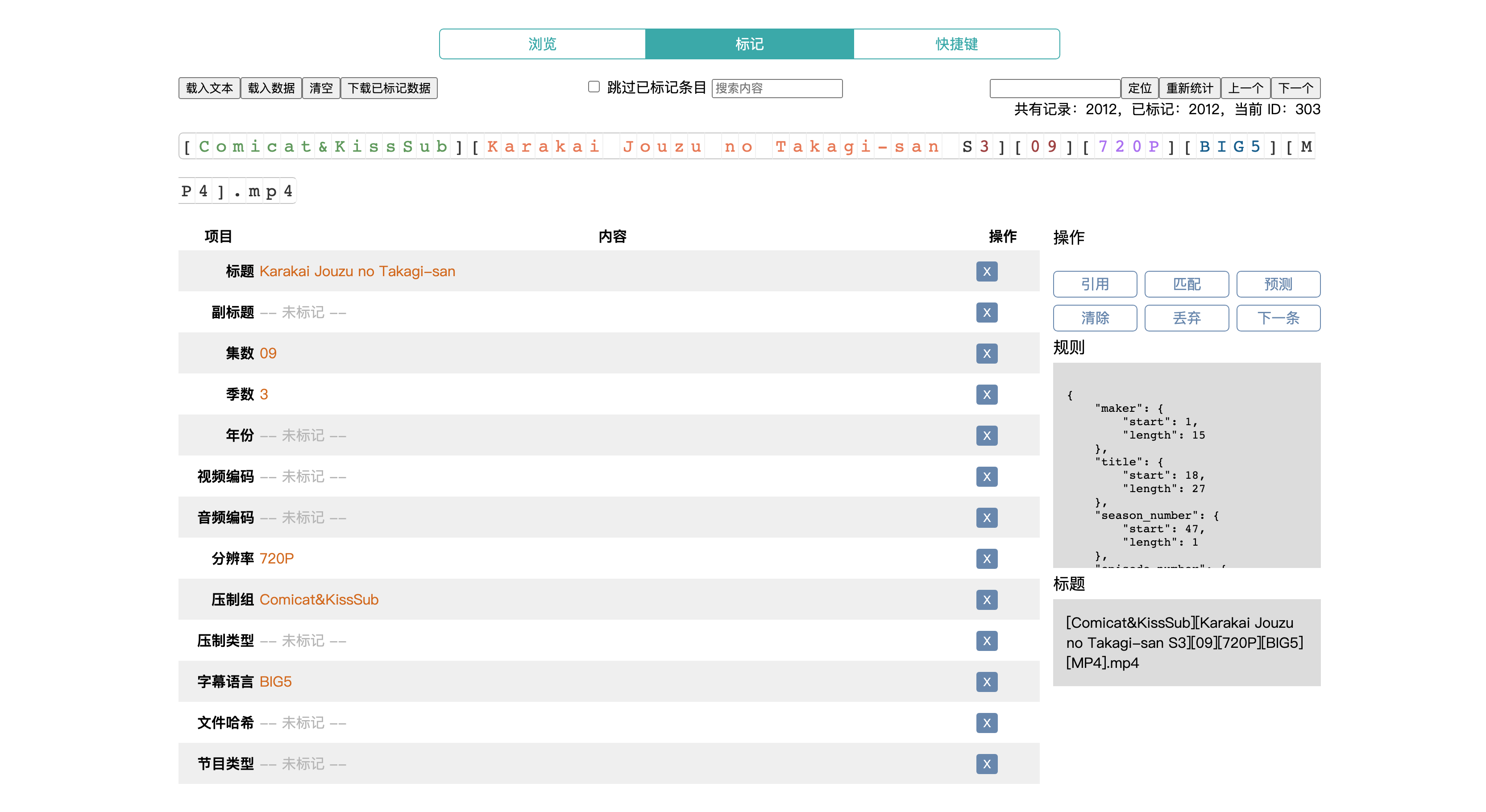
我写的面板大概这个样子,虽然外观不怎么好看,但是还是得拿出来炫耀一下。采用的是 Vue3,那也是 Vue3 正式版已经发布了几个月,正好用来练手。
这个标记面板实现了标记数据需要的核心功能:
- 数据持久化
- 数据导入导出
- 对接网页模型
- 标记字段可配置化
- 快捷键支持
第一个版本数据存储在内存里面,刷新一下就没有了,后面改为 indexedDB 存储数据,就不存在这个问题。
开始的时候数据需要自己标记,手动标记加上一些正则自动匹配。第二个阶段模型训练出来,就可以在网页段引入模型预测数据,外加自己手动修正一些数据,那时候标记效率非常的高,但是数据量提升对于模型的准确度却没什么提高,缺少泛化的数据,因此只能用作动画名称识别,对于不规则名称一点办法都没有。
ChatGPT 降维打击
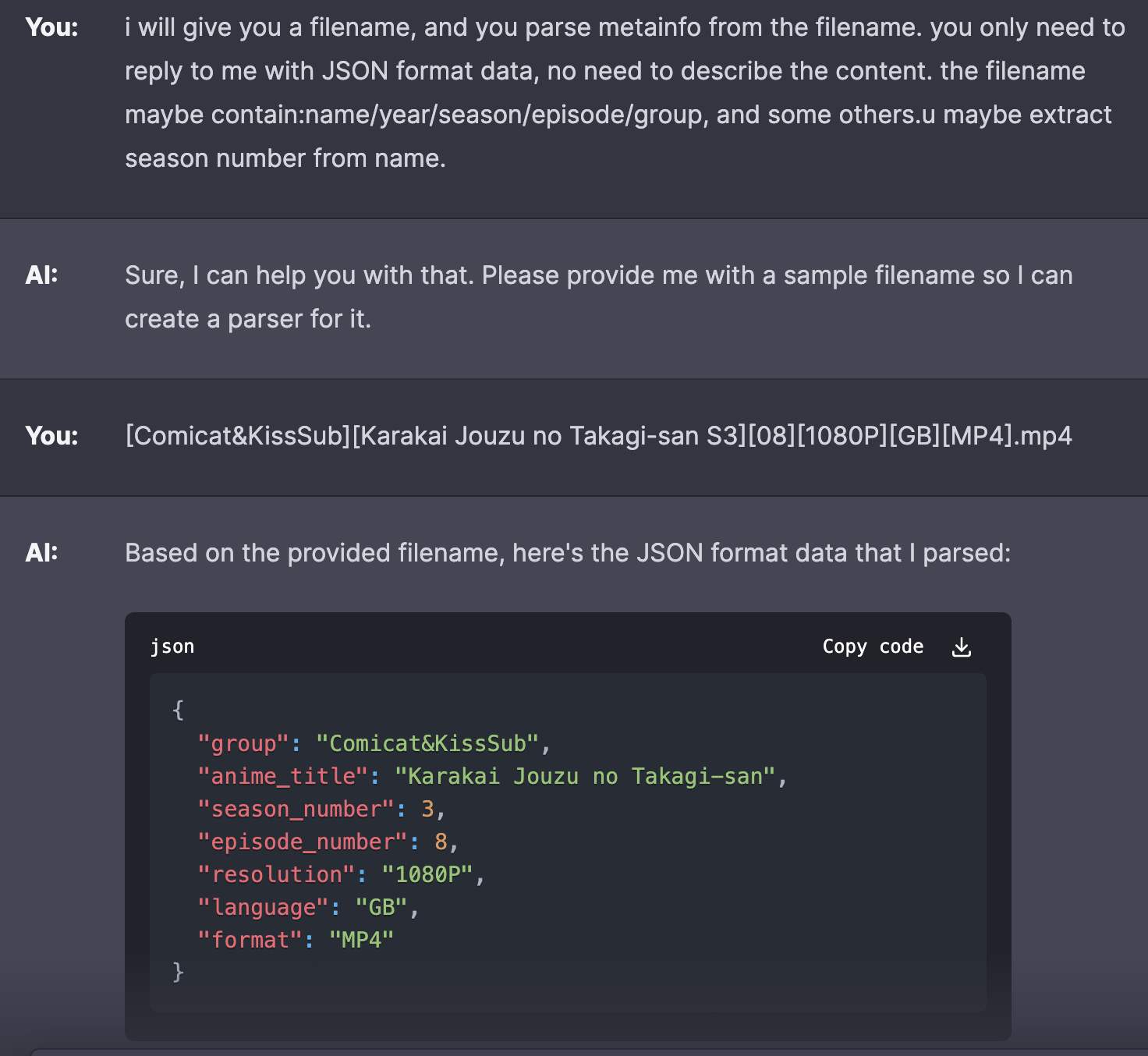
最近基于 OpenAI API 开发的各种应用,我也尝试了一下,即使是我喳喳的工地英语,它也能理解我想要的东西,真的太厉害了。如果使用接口开发一个能用的文件名解析器,半天的时间就足够了吧。
以前做网络开发,调用接口的时候,都是规定参数数量,传递格式。现在都是使用 prompt,各种描述功能,描述返回内容,这是非常奇幻的体验。